01
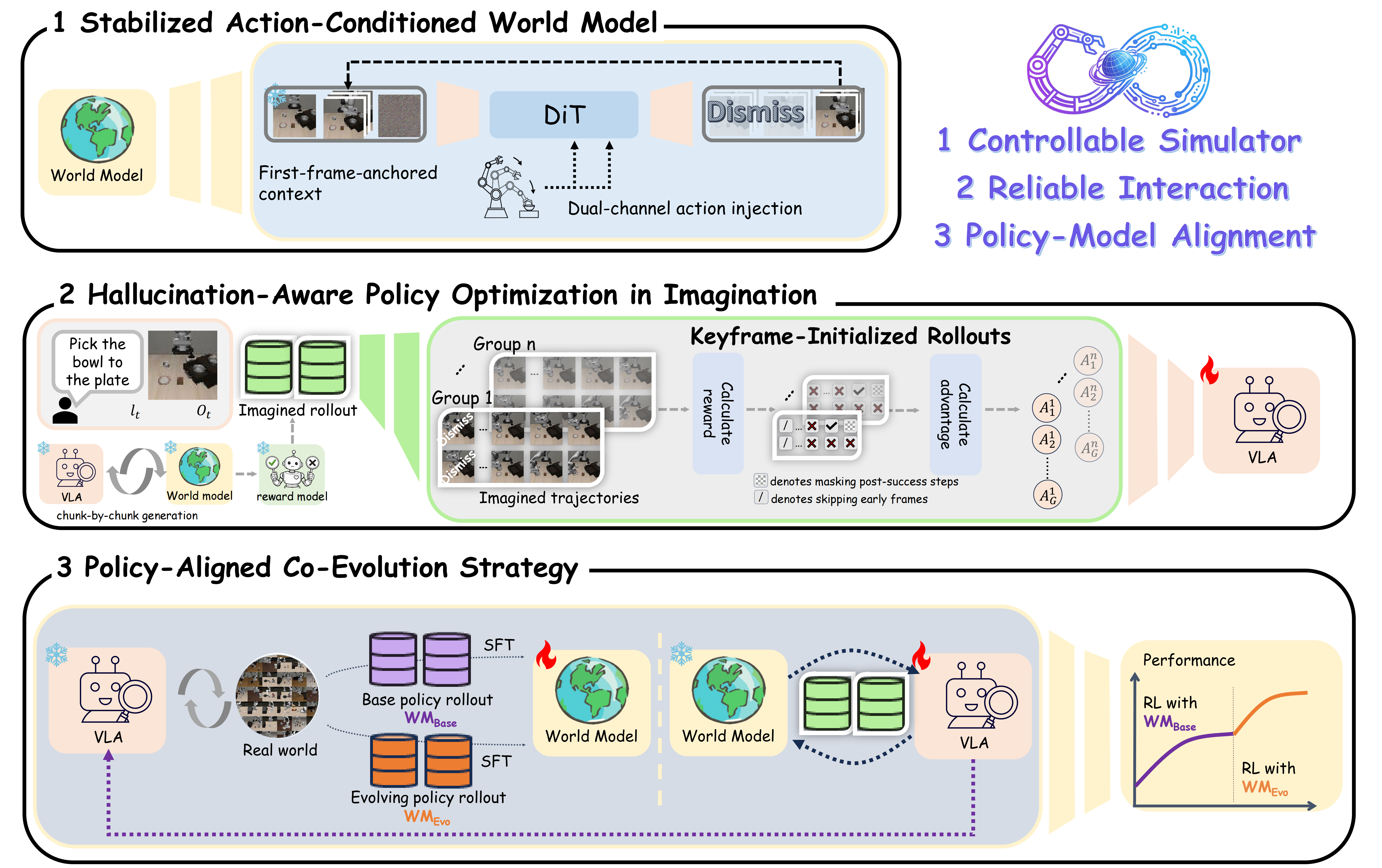
Stabilized Action-Conditioned World Model
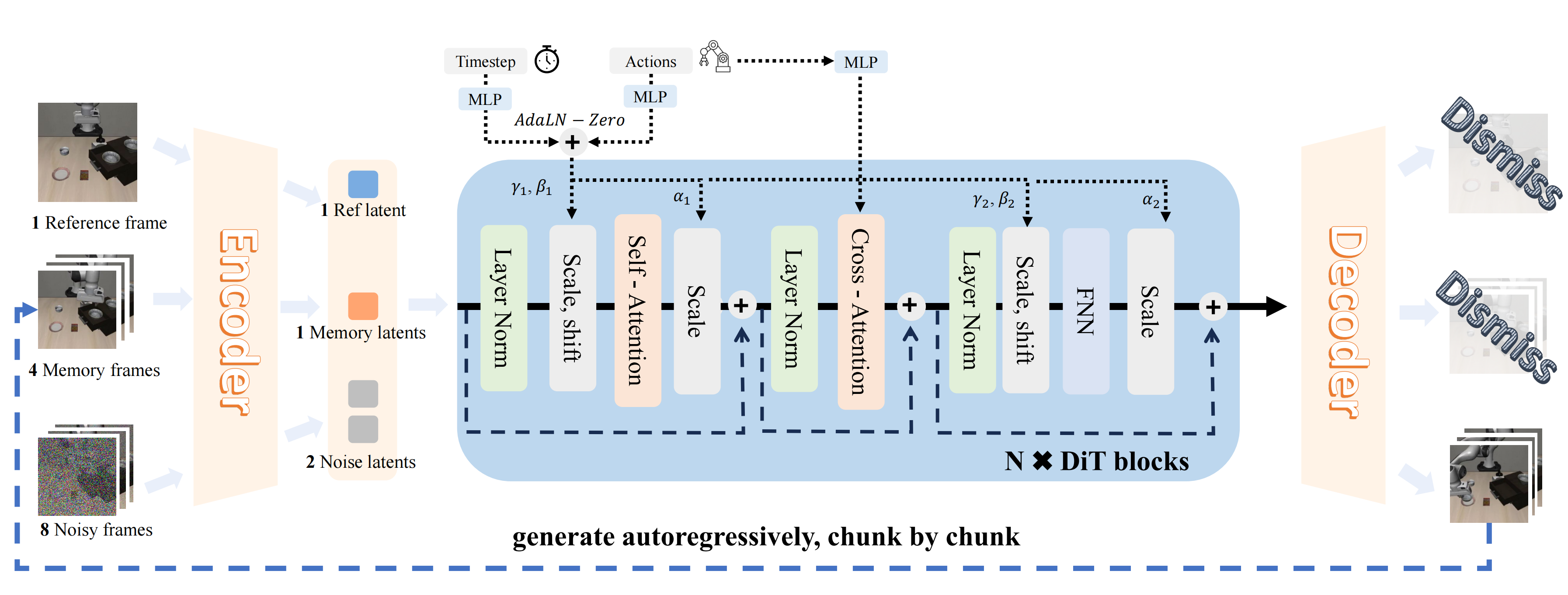
WoVR upgrades a video diffusion backbone into an action-controllable, rollout-stable simulator with dual-channel action injection and first-frame anchoring. This reduces long-horizon drift and keeps imagined trajectories responsive to policy actions.
- Dual-path action conditioning for local modulation and global control.
- First-frame anchoring to preserve scene structure across autoregressive chunks.
- Noisy context training to narrow the train-inference gap.